MTA train times

If you're taking a train to from work, and you do not always start/end the day at the same time, you'll want to know when the trains are.
MTA offer GTFS files of the Metro North train details, linked from their developer site https://new.mta.info/developers . Using those, some automation from https://n8n.io/, a little python and some shortcuts on the phone, we can figure out when the next trains are in only a little longer than it would take to open the regular MTA app.
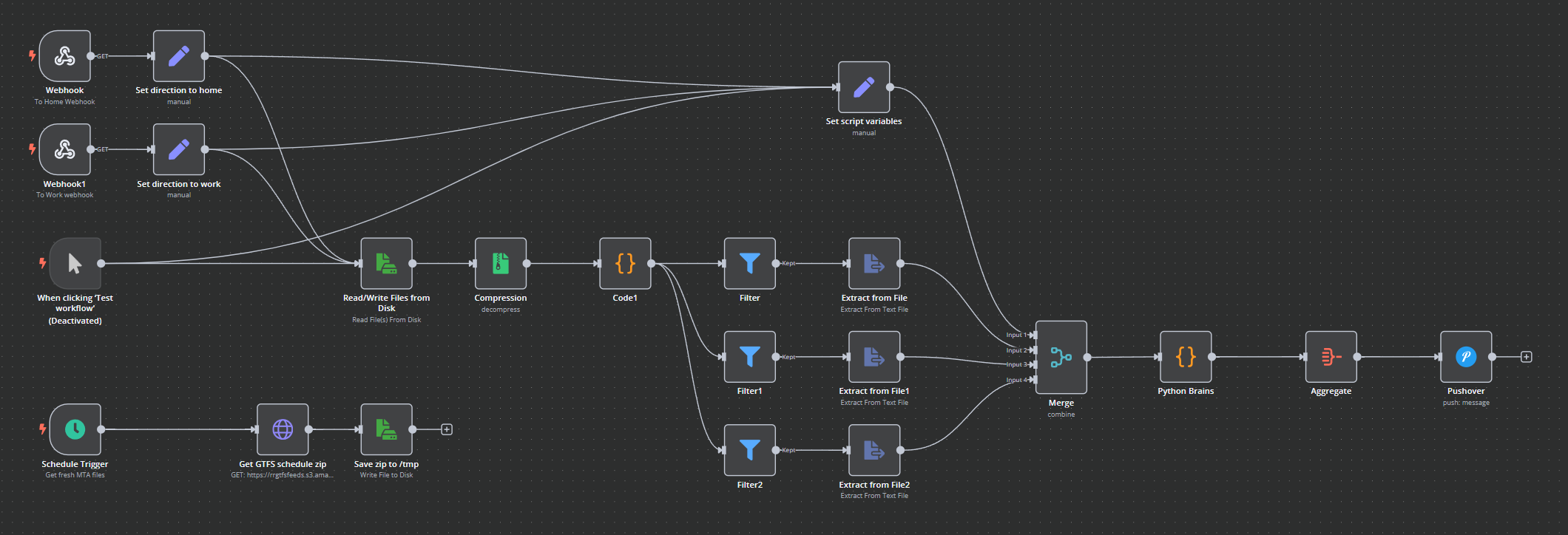
We start by downloading the GTFS files daily, this is done on a time trigger for some time on the early hours when most people are asleep.
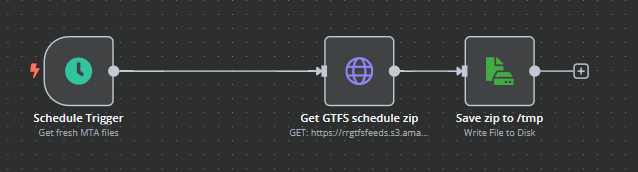
Those files are saved to disk so that we can read them when we want to get the times of the trains.
The workflow can be triggered from one of 2 webhooks, one for each direction of the journey.
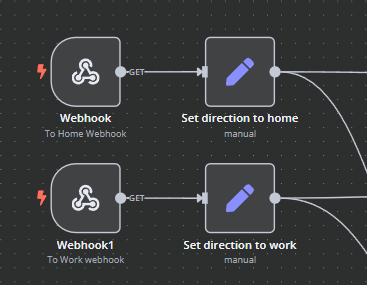
These are saved as "OpenURL" shortcuts in the iOS Shortcuts app, which lets you trigger them with "Hey Siri, next train home". Your phone (or watch) will then fire off a request to the webhook and trigger everything. Each webhook is linked to a step that sets the "direction" parameter so that we know which way we want to look up the trains.
We then read the zip file that we downloaded overnight, extract all the files, run it though a little JavaScript to get the data into the order we want, and the extract the csv data from the 3 files that we actually need in our python script.
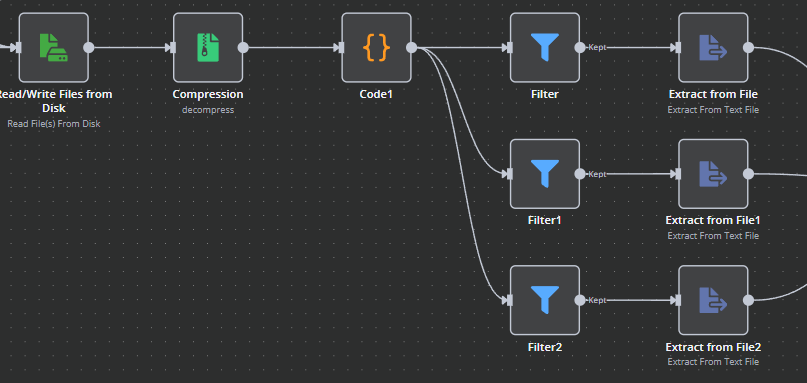
The code node there puts the binary data into an array for the next steps to work on.
let results = [];
for (item of items) {
for (key of Object.keys(item.binary)) {
results.push({
json: {
fileName: item.binary[key].fileName
},
binary: {
data: item.binary[key],
}
});
}
}
return results;
The output of those 3 files, plus some additional script variables that we set manually are merged and fed into the python script that does most of the heavy lifting.
The python node in N8N is based on pydiode, so has some quirks and limitations. It really didn't like global variables, so the code that worked on the real python interpreter needed some tweaks to make it happy in this psuedo-python setup.
import pandas as pd
from io import StringIO
import bisect
import dataclasses
import json
from dataclasses import field
df_calendar_dates = pd.read_csv(StringIO(_input.first().json.calendar_dates_data))
df_trips = pd.read_csv(StringIO(_input.first().json.trips_data))
df_stop_times = pd.read_csv(StringIO(_input.first().json.stop_times_data))
STOP_MAP = {
_input.first().json.HOME_STOP: _input.first().json.HOME_NAME,
_input.first().json.WORK_STOP: _input.first().json.WORK_NAME,
}
DIRECTION_MAP = {
0: f"To {_input.first().json.HOME_NAME}",
1: f"To {_input.first().json.WORK_NAME}",
}
to_home_commutes = []
to_work_commutes = []
def init(for_date, df_calendar_dates, df_trips, df_stop_times, to_home_commutes, to_work_commutes):
home_trips = df_stop_times[df_stop_times["stop_id"] == _input.first().json.HOME_STOP]["trip_id"].unique().tolist()
df_stop_times = df_stop_times[df_stop_times["trip_id"].isin(home_trips)]
services = df_calendar_dates[df_calendar_dates['date'] == int(for_date)]["service_id"].unique().tolist()
trips = (
df_trips[(df_trips["service_id"].isin(services)) & (df_trips["route_id"] == _input.first().json.ROUTE_ID)]["trip_id"]
.unique()
.tolist()
)
home_trips = df_stop_times[(df_stop_times["trip_id"].isin(trips)) & (df_stop_times["stop_id"].isin([_input.first().json.HOME_STOP, _input.first().json.WORK_STOP]))][_input.first().json.STOP_TIMES_COLS_TO_KEEP]
home_trips = pd.merge(home_trips, df_trips[["trip_id", "direction_id", "trip_short_name"]], on="trip_id", how="left")
to_home_trips = home_trips[home_trips["direction_id"] == 0]
to_work_trips = home_trips[home_trips["direction_id"] == 1]
for _, g in to_home_trips.groupby("trip_id"):
if len(g) == 2: # check we have the expected to/from rows
c = make_commute(g)
to_home_commutes.append(c)
for _, g in to_work_trips.groupby("trip_id"):
if len(g) == 2: # check we have the expected to/from rows
c = make_commute(g)
to_work_commutes.append(c)
to_home_commutes.sort()
to_work_commutes.sort()
print("Finished init")
return (to_home_commutes, to_work_commutes)
@dataclasses.dataclass(frozen=True, order=True)
class Commute:
departs_stop: str = field(compare=False)
departs_time: str = field()
departs_track: int = field(compare=False)
arrives_stop: str = field(compare=False)
arrives_time: str = field(compare=False)
arrives_track: int = field(compare=False)
direction: str = field()
trip_id: str = field(compare=False)
trip_short_name: int = field(compare=False)
def make_commute(df: pd.DataFrame) -> Commute:
row_0 = df.iloc[0]
row_1 = df.iloc[1]
c = Commute(
departs_stop=STOP_MAP[row_0["stop_id"]],
departs_time=row_0["departure_time"],
departs_track=row_0["track"],
arrives_stop=STOP_MAP[row_1["stop_id"]],
arrives_time=row_1["departure_time"],
arrives_track=row_1["track"],
direction=DIRECTION_MAP[row_0["direction_id"]],
trip_id=row_0["trip_id"],
trip_short_name=row_0["trip_short_name"],
)
return c
def get_trains(around_time, direction, to_home_commutes, to_work_commutes):
print(f"Getting trains for {around_time} in direction {direction}")
if direction == 0:
return get_trains_around_time(to_home_commutes, around_time)
elif direction == 1:
return get_trains_around_time(to_work_commutes, around_time)
else:
print(f"Invalid direction: {direction}")
def get_trains_around_time(commutes, the_time):
print(f"Getting select trains around {the_time}")
print(f"From {len(commutes)} commutes")
index = bisect.bisect_left(commutes, the_time, key=lambda c: c.departs_time)
missed_train = commutes[index - 1] if index > 0 else None
next_trains = commutes[index : index + 2] if index < len(commutes) else []
return [missed_train, *next_trains]
###### Main script here ####
print(f"Setting up for date: {_input.first().json.the_date}")
(to_home_commutes, to_work_commutes) = init(_input.first().json.the_date, df_calendar_dates, df_trips, df_stop_times, to_home_commutes, to_work_commutes)
print(f"Len of to_home_commutes: {len(to_home_commutes)}")
print(f"Len of to_work_commutes: {len(to_work_commutes)}")
print(f"Getting trains around {_input.first().json.the_time} going in direction {_input.first().json.direction}")
trains = get_trains(_input.first().json.the_time, _input.first().json.direction, to_home_commutes, to_work_commutes)
print(f"Number of trains returned: {len(trains)}")
print([str(t) for t in trains])
print(json.dumps([dataclasses.asdict(t) for t in trains if t is not None]))
return [dataclasses.asdict(t) for t in trains if t is not None]
This code merges and filters and reformats things to get the details of the train we just missed, and the next 2 trains. We get the train from just before the current time, as sometimes you just want to know how much you missed it by. We get the next 2 trains, as sometimes you are not going to make the very next train if it leaves in less time that it takes you to get to the station.
These datapoints are aggregated and passed to a Pushover node where they are formatted with some basic HTML and pushed out to my phone.
Trains: <br>
<b>{{ $json.data[0].departs_stop }} / {{ $json.data[0].departs_time }} / Track {{ $json.data[0].departs_track }} </b>
{{ $json.data[0].arrives_stop }} / {{ $json.data[0].arrives_time }} / Track {{ $json.data[0].arrives_track }}
Going {{ $json.data[0].direction }} [Trip: {{ $json.data[0].trip_short_name }}]
<b>{{ $json.data[1].departs_stop }} / {{ $json.data[1].departs_time }} / Track {{ $json.data[1].departs_track }} </b>
{{ $json.data[1].arrives_stop }} / {{ $json.data[1].arrives_time }} / Track {{ $json.data[1].arrives_track }}
Going {{ $json.data[1].direction }} [Trip: {{ $json.data[1].trip_short_name }}]
<b>{{ $json.data[2].departs_stop }} / {{ $json.data[2].departs_time }} / Track {{ $json.data[2].departs_track }} </b>
{{ $json.data[2].arrives_stop }} / {{ $json.data[2].arrives_time }} / Track {{ $json.data[2].arrives_track }}
Going {{ $json.data[2].direction }} [Trip: {{ $json.data[2].trip_short_name }}]
Crude, but effective and surprisingly handy.